1.steghide
遇到steghide可能只能试试,不知道有没有文件,但是使用
steghide info 文件
可以看到有没有文件
2.foremost与binwalk
foremost是 数据恢复工具,适合从原始数据中提取已知格式的文件。binwalk是 文件分析工具,适合逆向工程和提取嵌套结构。
所以当文件破损或者损坏的即可使用foremost
foremost指令参数
- -o:参数用于 指定恢复文件的输出目录
- – T:恢复文件,保留原始时间戳

- – i :参数用于 指定输入源
与 binwalk 的区别
| 功能 | foremost | binwalk |
| 主要用途 | 文件恢复(File Carving) | 文件分析(如固件解包) |
| 输入源 | 磁盘镜像、设备 | 文件、固件 |
| 恢复能力 | 擅长恢复已知格式(JPEG, PDF, ZIP) | 擅长分析嵌套结构(如压缩包、文件系统) |
| 时间戳 | 支持(-T) | 不支持 |
3.提取隐写(Extract Steganography)
LSB(Least Significant Bit,最低有效位)隐写提取是指从数字载体(通常是图像或音频文件)中提取通过修改最低有效位嵌入的隐藏信息的过程
python2 lsb.py extract 文件 文件名称 密码
- 统计检测:
- LSB隐写会改变像素值的统计特性
- 使用卡方检验可以检测异常分布
- 改进算法:
- LSB匹配:在修改时保持统计特性
- 随机LSB:使用加密密钥确定嵌入位置
4.SilentEye 隐写原理分析
SilentEye 主要通过修改载体文件(Cover File)的 最低有效位(LSB) 来嵌入隐藏数据,同时提供多种优化选项:
(1) LSB(最低有效位)隐写
- 图像隐写(BMP/PNG):
- 修改像素的 R/G/B 通道 的最低 1~2 位(取决于配置)。
- 例如,在 24 位 BMP 中,每个像素有 3 字节(RGB),可以隐藏 3 位数据(每个通道 1 位)。
- 对于 PNG,由于是无损压缩,LSB 修改后数据仍然可以正确提取。
- JPEG 隐写:
- JPEG 是有损压缩,直接修改像素会导致数据丢失。
- SilentEye 采用 DCT(离散余弦变换)系数微调 的方式嵌入数据,比普通 LSB 更复杂。
- 音频隐写(WAV):
- 修改音频采样点的 LSB,类似于图像隐写,但对听觉影响极小。
(2) 数据加密(AES-256)
- 可选 AES-256 加密隐藏数据,防止直接提取。
- 加密后的数据再嵌入 LSB,提高安全性。
| 工具 | 载体支持 | 加密 | 压缩 | 抗检测能力 |
| SilentEye | BMP/PNG/JPEG/WAV | AES-256 | zlib | 中等(LSB 易检测) |
| Steghide | JPEG/BMP/WAV | 无(可结合 GPG) | 有 | 较强(DCT 优化) |
| OpenStego | PNG/BMP | 无 | 有 | 较弱(纯 LSB) |
| DeepSound | WAV/FLAC | AES | 无 | 强(音频隐写) |
如何检测 SilentEye 隐写?
- 统计分析(如 卡方检测):
- LSB 隐写会改变像素值的统计分布。
- StegExpose 等工具:
- 专门检测 LSB 隐写的工具。
- AES 加密数据:
- 如果没有密码,即使检测到隐写也无法提取。
5.F5隐写原理
F5隐写算法(由德国研究员Andreas Westfeld提出),这是一种针对JPEG图像的改进型隐写技术,比传统LSB隐写更隐蔽,抗统计分析能力更强
基本原理
F5隐写主要基于 JPEG压缩域(DCT系数) 进行数据嵌入,核心思想是:
- 不直接修改DCT系数的LSB(容易被检测),而是采用 矩阵编码(Matrix Encoding) 和 系数扩散 的方式隐藏数据。
- 优先修改高频DCT系数(对图像质量影响较小)。
- 避免引入统计异常(如卡方检测难以发现)
6.FFC隐写原理
Free File Camouflage (FFC) 是一款专注于文件隐藏的隐写工具,其核心思想是将秘密文件伪装成普通文件(如JPG、MP3等),使外部观察者无法察觉隐藏数据的存在。以下是其技术原理分析:
FC 并不是传统的基于像素/音频采样的隐写术,而是采用文件结构拼接的方式隐藏数据,主要分为两种模式:
(1) 文件捆绑(File Binding)
- 将多个文件物理拼接成一个文件,利用格式容错性隐藏数据
- 例如:
- 把
secret.zip追加到image.jpg的末尾 - 生成的文件既能用图片查看器正常显示,又能用解压工具提取隐藏ZIP
(2) 载体替换(Carrier Substitution)
- 利用文件格式的未使用区域(如EXIF元数据、ID3标签)存储数据
- 例如:
- 在MP3文件的ID3v2标签中嵌入加密数据
- 在JPEG的注释字段(COM段)隐藏信息
7.pdf爆破
pdf爆破可以使用pdfcrack
pdfcrack -f pdf -w rockyou.txt -q
-f FILE:选择 FILE 文件
-b:执行基准测试并退出
-c STRING:使用 STRING 中的字符作为字符集
-w FILE:使用 FILE 作为密码源进行尝试
-n INTEGER:跳过尝试短于 INTEGER 的密码
-m INTEGER:达到此 INTEGER 密码长度时停止
-l FILE:从 FILE 中保存的状态继续
-o:使用所有者密码
-u:使用用户密码(默认)
-p STRING:提供用户密码以加快破解所有者密码的速度(隐含 -o)
-q:安静运行
-s:尝试排列密码(目前仅支持将第一个字符切换为大写)
-v:打印版本并退出8.stegseek
当题目需要使用steg但是没有说是什么可以使用stegseek
stegseek类似于steghide的密码爆破
stegseek 爆破对象 密码本 提出文件
- StegSeek 是Steghide专用破解工具,适合取证或安全测试。
- 依赖字典质量:建议使用
rockyou.txt或定制字典。 - 合法使用:仅用于授权渗透测试或文件恢复。
9.WbStego隐写
如何判断是否文件采用wbStego4open加密?
- 将文件导入010editor、winhex之类的十六进制查看工具
- 如果
20、09出现次数较多,则有可能为wbStego4open加密
10.GPS 数据隐写
GPS数据隐写是一种利用全球定位系统(GPS)数据文件作为载体进行信息隐藏的技术,主要应用于地理信息系统、位置数据共享和隐蔽通信等领域。以下是其核心原理和实现方法
如何发现GPS隐写
一般为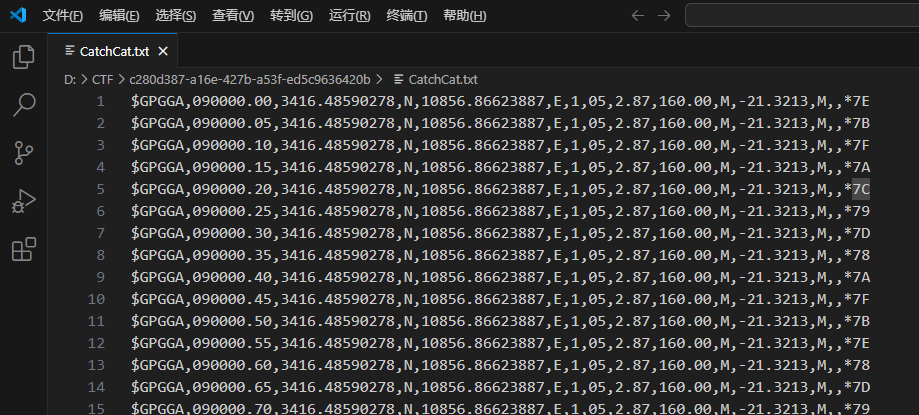
大量的GPS
去找在线GPS文件制作HTML地图得到flag
11.傅里叶变换
压缩包的名称为 FFT,明显的傅叶里变换
基本原理
- 傅里叶变换:将原始图像进行二维离散傅里叶变换(DFT),得到频域表示。频域图像的每个点包含幅度和相位信息,分别代表图像中不同频率成分的强度和位置
- 水印嵌入:选择频域中的特定区域(通常是中频区域)嵌入水印信息。为了保持频谱的对称性,通常会将水印对称地嵌入频域的两个区域。嵌入方式可以是直接修改幅度值,也可以通过相位调制等方法
- 傅里叶逆变换:将嵌入水印后的频域图像进行傅里叶逆变换,得到含有水印的空间域图像。由于水印嵌入在频域中,空间域图像的视觉质量变化较小,难以被察觉
- 水印提取:在不需要原始图像的情况下,对含水印图像进行傅里叶变换,提取频域中的水印信息。这就是“盲”水印的含义,即提取水印时不依赖原始图像
12.Private Bit 隐写

第一个是 0,第二个是 1
提前前八个得到 01000110,转为 ASCII 码是 F
以下是对于 struct MPEG_FRAME mf 的解析
| 名称 | 长度 (bit) | 作用 |
| syncword | 12 | 同步头,表示一帧数据的开始,共 12 位,全 1 即 0xFFF |
| ID | 1 | 算法标识位,”1″ 表示 MPEG 音频 |
| layer | 2 | 用来说明是哪一层编码 |
| protection_bit | 1 | 用来表明冗余信息是否被加到音频流中,以进行错误检测和错误隐蔽;”1″ 是未增加,”0″ 是增加 |
| bitrate_index | 4 | 用来指示该帧的 bitrate |
| sampling_frequency | 2 | 用来指示采样频率 |
| padding_bit | 1 | 如果该位为 1,那么帧中包含一个额外槽,用于把平均位率调节到采样频率,否则该位必须为 0 |
| private_bit | 1 | 留做私用 |
| mode | 2 | 定义通道模式 |
| mode_extension | 2 | 用来标识采用了哪一种 joint_stereo |
| copyright | 1 | 表明版权用,”1″ 表示有版权,”0″ 表示没有版权 |
| original/home | 1 | 表明原版还是复制,”1″ 表示原版,”0″ 表示复制 |
| emphasis | 2 | 表明加重音类型 |
一个 mf 的 HEADER 总共 12+1+2+1+4+2+1+1+2+2+1+1+2=32,即总共 4 字节
private_bit 为 24,所在的字节为第 3 个字节,因此该字节对应的地址为 235984+2=235986,即为第一个 private_bit 开始地址
可以发现在每个 MPEG_FRAME mf 下的 4 字节 MPEG_HEADER mpeg_hdr 中的第 24 个 bit 有一个 private bit
- 观察每一个 mf 组,大小为 417 或 418 字节,因此需要编写脚本
import re
def extract_hidden_data(file_path):
# ========== 参数设置部分 ==========
# 初始读取位置(第一个 private bit 的起始位置)
start_pos = 235986
# 结束读取位置(通过分析发现此位置后 private_bit 都为 0)
end_pos = 1369844
# 基本组大小
group_size = 417
# 需要跳过额外字节的位置集合(使用集合提高查找效率)
skip_positions = {0, 1, 26, 50, 75, 99, 124, 148, 173, 197,
222, 246, 271, 295, 320, 344, 369, 393, 418}
# ========== 数据提取部分 ==========
binary_data = [] # 用于存储提取的二进制位
current_pos = start_pos # 当前文件指针位置
counter = 0 # 位置计数器
with open(file_path, 'rb') as file:
while current_pos < end_pos:
# 移动文件指针到当前位置
file.seek(current_pos)
# 决定前进的步长:
# - 如果在 skip_positions 中,前进 group_size(417)
# - 否则前进 group_size + 1(418)
step = group_size if counter in skip_positions else group_size + 1
current_pos += step
# 读取 1 个字节
byte = file.read(1)
if not byte: # 如果读到文件末尾则终止
break
# 提取字节的最后一位(使用位运算比bin()更高效):
# 1. ord(byte) 获取字节的整数值
# 2. & 1 获取最低位
# 3. str()转换为字符串形式('0'或'1')
binary_data.append(str(ord(byte) & 1))
counter += 1 # 位置计数器递增
# ========== 数据处理部分 ==========
# 将二进制位列表拼接成字符串
binary_str = ''.join(binary_data)
# 使用正则表达式将二进制字符串按 8 位一组分割
# 然后将每组二进制转换为对应的 ASCII 字符
hidden_text = ''.join([
chr(int(byte, 2)) # 将 8 位二进制字符串转换为整数再转换为字符
for byte in re.findall('.{8}', binary_str) # 每 8 位分割
])
# 返回处理后的文本(去除首尾空白字符)
return hidden_text.strip()
if __name__ == '__main__':
result = extract_hidden_data('1.mp3')
print(result)13.采样率隐写

看不起
只好调整一下采样率
发现900是最好的
14.波形隐写(Wav)
波形隐写原理就是将波形的高低转为二进制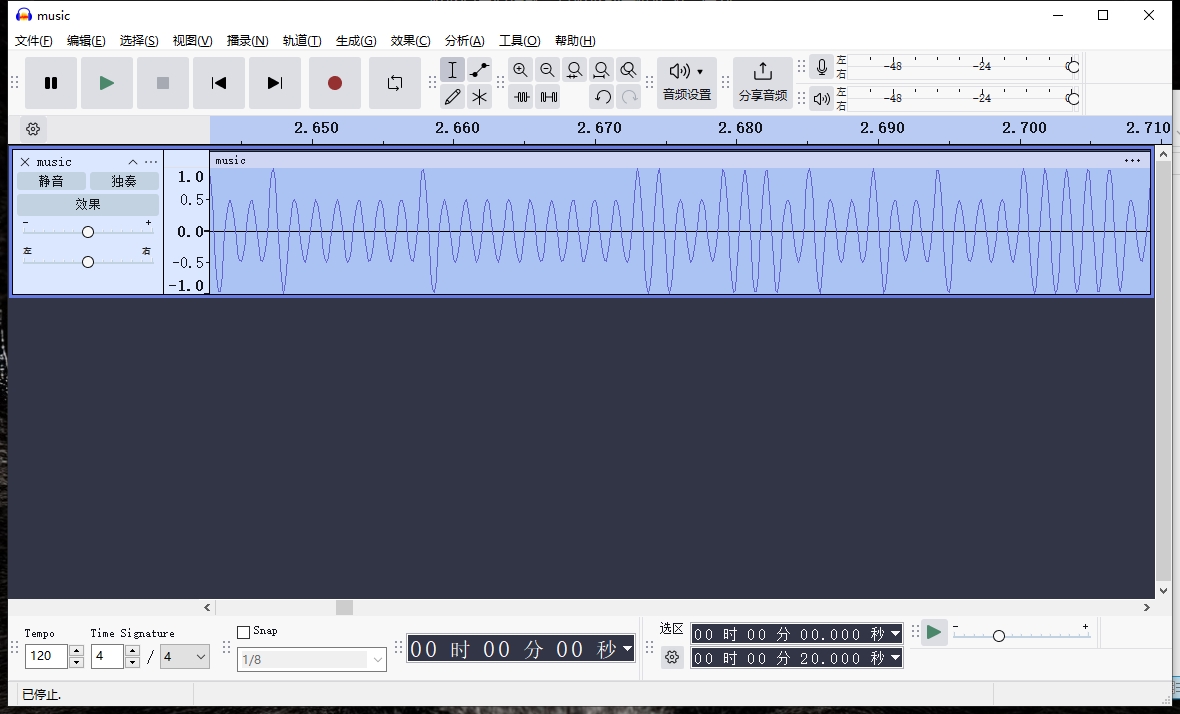
import wave
import numpy as np
def main():
wavfile = wave.open('music.wav', "rb")
# 获取 WAV 文件的参数
params = wavfile.getparams()
# 获取音频的采样点数
nframes = params[3]
# 从 WAV 文件中读取所有帧的数据
datawav = wavfile.readframes(nframes)
wavfile.close()
# 将读取的二进制数据(datawav)转换为一个 NumPy 数组,数据类型为短整型(np.short)
datause = np.frombuffer(datawav, dtype=np.short)
result_bin = ''
# 记录当前的最大值
mx = 0
# 循环遍历 datause 数组,除了最后一个元素
for i in range(len(datause) - 1):
# 更新记录最大值的变量 mx
if datause[i] > mx:
mx = datause[i]
# 检查当前元素是否为负数且下一个元素为非负数
# 如果是,这意味着音频波形从负数跨越到0或正数,这可能是隐藏数据的标记点
if datause[i] < 0 <= datause[i + 1]:
# 检查从负数到非负数的跨越是否足够大(大于24000)
# 用于区分隐藏数据位是 '1' 还是 '0' 的阈值
if mx - 24000 > 0:
result_bin += '1'
mx = datause[i + 1]
else:
result_bin += '0'
mx = datause[i + 1]
result_hex = ''
# 将二进制数据转换为十六进制
for i in range(0, len(result_bin), 4):
result_hex += hex(int(result_bin[i: i + 4], 2))[2:]
print(result_hex)
if __name__ == '__main__':
main()15.音频倒放隐写
先ctrl+A
将文件反向时间
即可音频倒放

16.Velato 编译隐写(Mid)
MIDI 文件优先考虑 Velato 编译
Velato 是一种编程语言,使用 MIDI 文件作为源代码,音符模式决定命令
发现mid音频后缀
即可使用velato


首先输入
Vlt.exe music.mid
会生成一个music.exe
在进行这个music.exe
得到一个数字
from Crypto.Util.number import *
long_to_bytes(4642488275724448709921860001805542920743247922240305533)
得到flag
做的很乱,请师傅见谅
刚开始是想写一个介绍工具原理的文章,但是不知不觉写了一个类似于隐写积累的文章
17.PDFStreamDumper工具原理解析
1. PDF 文件结构解析
- PDF 文件由对象(Objects)组成,包括字典(Dictionary)、数组(Array)、字符串(String)、流(Stream)等。恶意代码常隐藏在流对象(如
/JS、/JavaScript、/EmbeddedFile)中。 - PDFStreamDumper 通过解析 PDF 的交叉引用表(XRef Table)和对象层级结构,定位所有流对象,并提取其原始数据。
2. 流(Stream)对象处理
- 流对象是存储二进制数据或压缩数据的容器,通常由
<< ... >>字典和stream...endstream标记包围。 - 工具会解析流的字典属性(如
/Filter),判断是否经过压缩或编码(常见压缩方式:/FlateDecode、/ASCIIHexDecode、/LZWDecode)。 - 通过调用对应的解码库(如 zlib 解压
FlateDecode),还原流中的原始数据。
3. JavaScript 代码提取
- 恶意 PDF 常通过
/JS或/JavaScript对象嵌入恶意脚本。工具会:
- 提取流中的 JavaScript 代码。
- 处理可能的二次编码(如十六进制、Unicode 转义)。
- 反混淆代码(如
eval()动态执行、变量名混淆等)。
18.minimodem
minimodem 是一个命令行工具,用于通过音频(如声卡或音频线)实现简单的调制解调通信。它支持多种调制方式(如 FSK、PSK),常用于低速率数据传输或模拟传统调制解调器的场景。以下是它的典型使用场景:
1. 模拟传统调制解调通信
- 通过音频传输数据:比如在两台计算机之间通过声卡或音频线(如3.5mm音频线)发送文本或文件。
- 替代硬件调制解调器:在没有硬件调制解调器时,用软件模拟(如通过电台、电话线路等)。
用法为
minimodem –rx -f 文件 1200
| 选项 | 说明 |
-t, --tx | 发送(调制)模式 |
-r, --rx | 接收(解调)模式 |
-f, --frequency | 指定载波频率(Hz),默认 1200(FSK) |
-S, --space | 指定“0”比特频率(FSK 模式) |
-M, --mark | 指定“1”比特频率(FSK 模式) |
-c, --continuous | 持续发送(不自动停止) |
-q, --quiet | 静默模式(减少输出) |
-v, --verbose | 详细模式(调试用) |
-l, --list | 列出支持的调制方式 |
-s, --stopbits | 设置停止位(1 或 2) |
-p, --parity | 设置奇偶校验(none/odd/even) |
-8, --8bits | 使用 8 位数据(默认 7 位 ASCII) |
-A, --alsa | 使用 ALSA 音频接口(Linux) |
-P, --pulseaudio | 使用 PulseAudio(Linux) |
19.Git
Git 是什么
Git是一个版本管理控制系统(缩写VCS),它可以在任何时间点,将文档的状态作为更新记录保存起来,也可以在任何时间点,将更新记录恢复回来。
常用命令
提交步骤
git init 初始化git仓库 (mac中Command+Shift+. 可以显示隐藏文件)
git status 查看文件状态
git add 文件列表 追踪文件
git commit -m 提交信息 向仓库中提交代码
git log 查看提交记录
git reset --hard 是 Git 中一个 强制重置 命令,它会 彻底丢弃当前工作目录和暂存区的所有更改,并将 HEAD 指针、索引(暂存区)和工作目录 全部重置 到指定的提交状态。
作用
- 丢弃所有未提交的更改(包括工作目录和暂存区的修改)。
- 强制回退到某个提交(包括代码、文件状态和提交历史)。
- 危险操作:它会 永久删除未提交的更改,无法通过普通方法恢复!
基本语法
bash
复制
下载
git reset –hard <commit-hash>
<commit-hash>可以是:
HEAD~1(回退到上一个提交)a1b2c3d(某个具体的 commit hash)- 分支名(如
main)
如果不指定 commit,默认回退到 HEAD(即当前状态,但会清空未提交的更改)。
20.Firepwd
首先我们知道(json:记录文件 db:密钥文件)
ogins.json文件:将用户所有登录信息(包括URL,用户名,密码和其他元数据)存储为JSON。值得注意的是,这些文件中的用户名和密码均经过3DES加密,然后经过ASN.1编码,最后写入base64编码的文件中,用一个测试登录信息如下所示,其中encryptedUsername和encryptedPassword就是被加密的用户名和密码
所以我们需要解密Mozilla加密的密码
$ python firepwd.py -h
用法:firepwd.py [选项]
选项:
-h, –help 显示帮助信息并退出
-v VERBOSE, –verbose=VERBOSE
日志详细程度
-p MASTERPASSWORD, –password=MASTERPASSWORD
主密码
-d DIRECTORY, –dir=DIRECTORY
目录路径
$ python firepwd.py -d /用户路径/Mozilla/Firefox/配置文件/…
$ python firepwd.py -p ‘您的主密码’ -d 数据库路径/
$ python firepwd.py -v 2 -p ‘MISC*’ -d 指定目录/
下载链接:https://github.com/lclevy/firepwd
. FirePWD 解密流程
FirePWD 的工作步骤如下:
步骤 1:提取加密密钥
- 从
key4.db中读取加密的主密钥(Master Key)。
- 在 Windows 下,主密钥通过 DPAPI(数据保护 API)加密存储,FirePWD 会调用
CryptUnprotectData函数自动解密(无需用户干预)。 - 在 Linux/macOS 下,可能依赖系统密钥环(如 GNOME Keyring 或 KWallet)。
步骤 2:解密密码数据
- 从
logins.json中读取加密的密码(字段为encryptedUsername和encryptedPassword),这些数据通过 AES-256-GCM 或 3DES(旧版)加密。 - 使用步骤 1 获取的主密钥解密密码数据。
步骤 3:处理主密码(若存在)
- 如果 Firefox 配置了主密码,FirePWD 需要用户输入主密码才能派生解密密钥。否则直接使用
key4.db中的密钥。
步骤 4:输出明文密码
- 将解密后的用户名和密码以明文形式显示或导出。
FirePWD 的本质是利用 Firefox 密码存储机制的漏洞(依赖操作系统加密且无主密码时易解密),通过逆向 NSS 和操作系统 API 实现密码恢复。其有效性凸显了浏览器保存密码的潜在风险,用户需权衡便利性与安全性。
PGP定义
Pretty Good Privacy(PGP)是一个加密程序,为数据通信提供加密隐私和身份验证。PGP 用于对文本、电子邮件、文件、目录和整个磁盘分区进行签名、加密和解密,并提高电子邮件通信的安全性。PGP加密使用散列,数据压缩,对称密钥加密,最后是公钥加密的串行组合。其中最关键的是两种形式的加密的组合:对称密钥加密(Symmetric Cryptography)和非对称密钥加密(Asymmetric cryptography)。
PGP工作原理
在实现PGP加密的过程中,首先使用对称密钥加密算法对原始数据进行加密。对称密钥加密算法包括DES、AES、Blowfish等,这些算法能够快速地加密和解密数据,但是需要发送方和接收方之间共享密钥。
为了避免在网络上传输密钥,PGP使用了公钥加密算法。公钥加密算法是一种使用不同的密钥加密和解密的算法,其中公钥用于加密,而私钥用于解密。公钥加密算法包括RSA、DSA等,这些算法具有极高的安全性,但是加密和解密速度比对称密钥加密算法慢得多。
PGP将对称密钥加密,并使用接收方的公钥进行加密。这种方式可以保证密钥的安全性,同时可以确保只有接收方可以解密对称密钥,从而保护了数据的机密性。接收方使用自己的私钥对加密的对称密钥进行解密,然后使用对称密钥对数据进行解密。这种方式既可以保护数据的安全性,也可以提高加解密的速度。

PGP工作原理示意图
PGP 使用两种类型的加密算法来保护数据:对称密钥加密和公钥加密。对称密钥加密是一种使用相同密钥加密和解密的算法,因此在加密和解密之间需要共享密钥。而公钥加密则是一种使用不同的密钥加密和解密的算法,其中公钥用于加密,而私钥用于解密。下面我将简单介绍一下这两种算法的工作原理。
对称密钥加密
对称密钥加密是一种使用相同密钥加密和解密的算法,因此在加密和解密之间需要共享密钥。对称密钥加密的过程如下:
- 发送方选择一个加密密钥,并使用它将原始数据加密。
- 加密后的数据被发送到接收方。
- 接收方使用相同的密钥将加密的数据解密。
尽管对称密钥加密非常高效,但它有一个明显的缺点,即需要在发送方和接收方之间共享密钥。如果这个密钥被黑客或其他人获取,数据将无法得到保护。为了解决这个问题,PGP 使用了另一种加密算法:公钥加密。
公钥加密
公钥加密是一种使用不同的密钥加密和解密的算法,其中公钥用于加密,而私钥用于解密。公钥加密的过程如下:
- 发送方获取接收方的公钥,并使用它将对称密钥加密。
- 加密后的对称密钥和加密后的数据被发送到接收方。
- 接收方使用自己的私钥将加密的对称密钥解密。
- 接收方使用解密后的对称密钥将加密的数据解密。
公钥加密允许发送方使用接收方的公钥加密数据,而无需共享对称密钥。这样,即使黑客获得了加密后的数据,也无法使用它,因为他们没有接收方的私钥来解密对称密钥。
PGP示例
我用常用的加密电子邮件来举个例子,具体的工作流程是:
用户A要给用户B发送邮件。
- 用户B生成一对密钥(公钥和私钥),将公钥发送给用户A。
- PGP软件使用算法生成一个随机的会话密钥,这个密钥是一个很大的数字,而且只使用一次。
- 用户A用刚刚生成的密钥,加密邮件,并使用用户B的公钥对该密钥进行加密。
- 最后,用户A将加密的邮件及密钥发送给用户B,用户B使用自己的私钥进行解密,得到会话密钥,进而可以解密完整的邮件。
PGP加密用途
PGP有三个主要用途:
- 发送和接收加密电子邮件。
- 验证向您发送此消息的人员的身份,即数字签名验证。
- 加密数据。
其中,发送安全电子邮件 – 是迄今为止PGP的主要应用。数字签名是一种基于公钥加密的技术,用于证明信息的发送者身份和信息完整性,以及防止信息被篡改。发送方使用自己的私钥对消息的摘要进行加密,生成数字签名。接收方使用发送方的公钥对数字签名进行解密,并生成消息的摘要,比对两个摘要是否一致,来验证消息的完整性和身份。如果数字签名验证失败,则说明消息可能被篡改或者来自伪造的发送方。
总结
PGP使用对称密钥加密算法保护数据机密性,使用公钥加密算法保护对称密钥的安全性,使用数字签名技术验证消息的完整性和身份。这种结合了对称密钥和公钥加密的方法,可以在安全性和效率之间取得平衡。PGP已经成为一种被广泛应用的数据加密和数字签名的标准,保护了用户的隐私和安全。